引用datax官方描述:
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
因业务需要和三方系统交互,数据同步采用jdbc连接三方库方式进行数据同步,优点是灵活性强,比如可以在同步数据的时候做一些扩展性的操作,缺点是随着复杂度增长,以及三方库的增多,导致资源消耗越来越多,很容易出现性能问题。在此调研采用datax来同步数据,笔记如下:
1:下载dataX:
Gitee.com![]() https://gitee.com/link?target=https%3A%2F%2Fdatax-opensource.oss-cn-hangzhou.aliyuncs.com%2F202308%2Fdatax.tar.gz
https://gitee.com/link?target=https%3A%2F%2Fdatax-opensource.oss-cn-hangzhou.aliyuncs.com%2F202308%2Fdatax.tar.gz
2:上传到linux服务器,rz命令,上传后解压到某目录,我直接解压没指定目录
Tar -zxvf datax.tar.gz
3:进入datax目录验证是否成功
python bin/datax.py job/job.json,
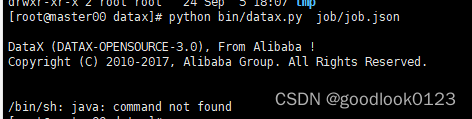
如出现上图为没有安装Java环境,上传jar到服务器后在etc/profile中配置目录即可
export JAVA_HOME=/home/java/jdk1.8.0_361
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$JAVA_HOME/bin:$PATH
Source /etc/profile 即可使配置文件生效,执行Java -version

4:再次执行:python bin/datax.py job/job.json
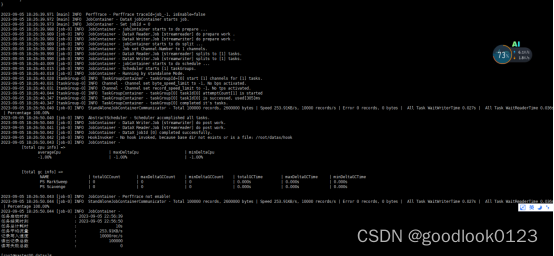
进行到这一步表示安装完成
5:配置
Sqlserverreader
{
"name": "sqlserverreader",
"parameter": {
"username": "",
"password": "",
"connection": [
{
"table": [],
"jdbcUrl": []
}
]
}
}
Mysql:
{
"name": "mysqlreader",
"parameter": {
"username": "",
"password": "",
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"where": ""
}
}
6:启动后:python bin/datax.py job/warehouse-cq.json
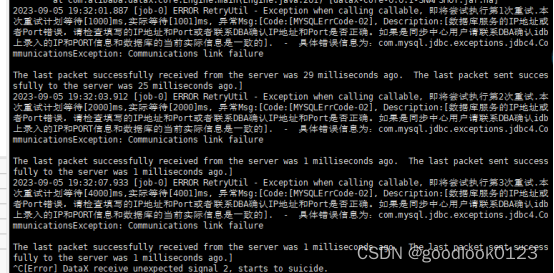
这个问题是因为url配置有问题
正确配置:
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["jdbc:sqlserver://219.153.111.**:**337;DatabaseName=***1076"],
"querySql": ["SELECT a.spid as erp_product_id,a.ckid as warehouse_id,sum(a.shl) as stock_num FROM phspkc AS a LEFT JOIN zl_spzl zs ON a.spid = zs.spid LEFT JOIN phzykc AS b ON a.spid= b.spid AND a.jwhid= b.jwhid AND a.pici= b.pici AND a.hzid= b.hzid LEFT JOIN zl_Hzzl z on a.hzid = z.hzid INNER JOIN zl_ckzl AS c ON a.ckid= c.ckid LEFT JOIN ( SELECT hzid,spid,pici,jwhid,SUM(shl) AS shl FROM dszykc GROUP BY hzid,spid,pici,jwhid ) AS d ON a.spid= d.spid AND a.jwhid= d.jwhid AND a.pici= d.pici AND a.hzid= d.hzid WHERE 1=1 GROUP BY a.spid, a.ckid, a.pici, a.pihao, a.sxrq, a.baozhiqi, a.jlgg, a.rkrq, a.djbh, a.hzid, z.hzmch, a.wldwid, a.dangqzht, a.jwhid, zs.spbh"]
}
],
"password": "*****",
"username": "**"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["erp_product_id","warehouse_id","stock_num"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.0.184:3307/ydw-middleground-dev?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false",
"table": ["warehouse_stock"]
}
],
"password": "******",
"preSql": ["truncate table warehouse_stock"],
"session": [],
"username": "****",
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
7:全量同步数据,同步成功
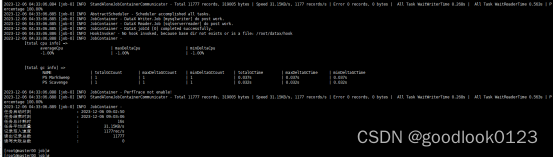
8:配置定时
查看是否已配置定时任务:crontab -l
若未配置:no crontal for xxx

创建crondatax文件:vim crondatax
编辑内容,十分钟运行一次:
0,10,20,35,44,50 * * * * python /root/datax//bin/datax.py /root/datax/job/warehouse-cq.json >>/home/datax/logs/corndataxlog.`date +\%Y\%m\%d\%H\%M\%S` 2>&1,
重启定时任务